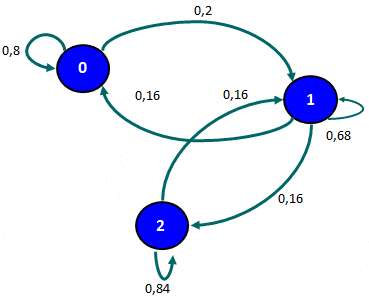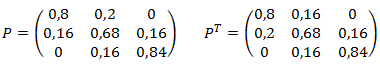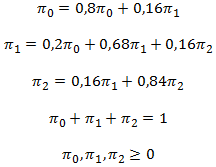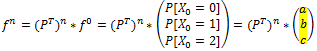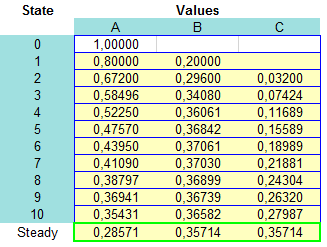
Un Árbol de Decisión (o Árboles de Decisiones) es un método analítico que a través de una representación esquemática de las alternativas disponible facilita la toma de mejores decisiones, especialmente cuando existen riesgos, costos, beneficios y múltiples opciones. El nombre se deriva de la apariencia del modelo parecido a un árbol y su uso es amplio en el ámbito de la toma de decisiones bajo incertidumbre (Teoría de Decisiones) junto a otras herramientas como el Análisis del Punto de Equilibrio.
Los árboles de decisión son especialmente útiles cuando:
- Las alternativas o cursos de acción están bien definidas (por ejemplo: aceptar o rechazar una propuesta, aumentar o no la capacidad de producción, construir o no una nueva bodega, etc.)
- Las incertidumbres pueden ser cuantificadas (por ejemplo: probabilidad de éxito de una campaña publicitaria, probable efecto en ventas, probabilidad de pasar de etapas, etc.)
- Los objetivos están claros (por ejemplo: aumentar las ventas, maximizar utilidades, minimizar costos, etc.)
Árbol de Decisión (Ejercicio Resuelto)
La gerencia de una tienda debe decidir si debe construir una instalación pequeña o grande en otra ciudad. La demanda ahí puede ser baja o alta, con probabilidades estimadas de un 40% y 60%, respectivamente. Si se construye la instalación pequeña y la demanda resulta ser alta, el gerente puede decidir no expandirse (ganancia $223) o expandirse (ganancia $270). Si se construye una instalación pequeña y la demanda es baja, no hay razón para expandirse y la ganancia estimada en este caso es de $200. Por otro lado si se construye una instalación grande y la demanda resulta ser baja , la opción es no hacer nada (ganancia $40) o estimular la demanda con publicidad local. La respuesta a la publicidad puede ser modesta o considerable, con probabilidades estimadas de un 30% y 70%, respectivamente. Si es modesta, la ganancia estimada será sólo de $20; si la respuesta es considerable, la ganancia aumenta a $220; y por último, si construye una instalación grande y la demanda resulta ser alta, la ganancia estimada es de $800.
Dibuje un árbol de decisiones. Después analícelo para determinar el pago esperado de cada decisión y nodo de evento. ¿Qué alternativa tiene la ganancia esperada más alta?.
Para estos efectos es importante comprender la nomenclatura comúnmente utilizada para representar un árbol de decisión.
- Los nodos de decisión se anotan como cuadrados.
- Los nodos de incertidumbre se anotan como círculos.
- Los nodos de resultados finales se anotan como triángulos.
- Los eventos se unen con líneas o ramas del árbol.
- Los costos o beneficios asociados a una decisión o evento se anotan en la rama (para efectos de recordar aplicarlos al final de esa rama).
- Las probabilidades de un evento se anotan entre paréntesis en la rama correspondiente a ese evento.
- Los valores asociados a cada pago final se anotan junto al triangulo correspondiente, e incluyen costos asociados a la rama.
- Se diseñan comenzando por la decisión inicial, y una rama a la vez. Es importante tener claro el orden temporal de los eventos.
- Es importante distinguir entre eventos sobre los cuales se tiene poder de decisión, y aquellos que no.
- Se debe estimar el valor o resultado final de cada extremo del árbol.
- Se deben estimar o calcular las probabilidades de ocurrencia de los eventos inciertos.
- Se deben estimar los correspondientes valores esperados para cada rama del árbol. La resolución es hacia atrás.
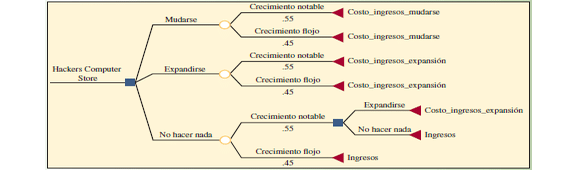
A continuación se muestra un ejemplo de dicha notación aplicada a un problema descrito en el libro Administración de Operaciones, Producción y Cadena de Suministros, Duodécima Edición, Página 131, de los autores Chase, Jacobs y Aquilano. En dicha representación gráfica se puede apreciar la utilización de los elementos descritos en la nomenclatura anteriormente.
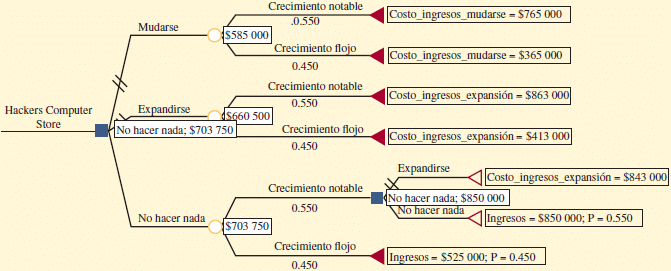
En relación a nuestro ejemplo utilizaremos el software POM for Windows el cual se encuentra disponible junto al libro Administración de Operaciones, Procesos y Cadena de Suministro, Décima Edición, de los autores Krajewski, Ritzman y Malhotra. Notar que la versión del software utilizado no dispone de la opción de resultado final (triángulo) por tanto se ha dado término a cada ramificación utilizando un nodo (círculo) de incertidumbre.
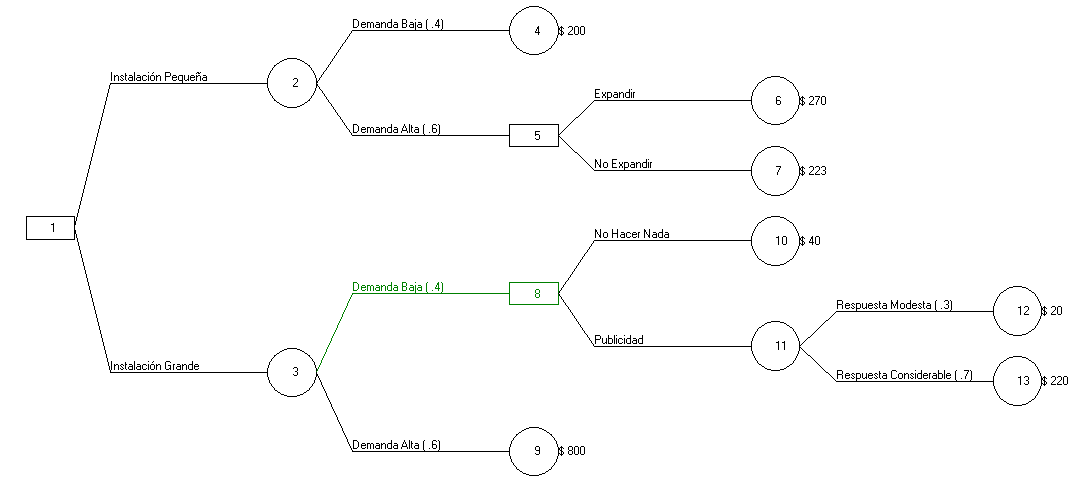
De esta forma la primera decisión consiste en construir una instalación pequeña o grande. Si la instalación es pequeña y la demanda es baja (con probabilidad de un 40%) no se hace nada y se obtiene $200 de ganancia, sin embargo, si la instalación es pequeña y la demanda es alta (con probabilidad de un 60%), nos enfrentamos a una segunda decisión: expandirse (con ganancia estimada de $270) o no expandirse (con ganancia estimada de $223).
Por otro lado si se decide por una instalación grande la demanda puede ser alta (con probabilidad de un 60%) en cuyo caso la ganancia es de $800 (y no se hace nada más) o la demanda puede ser baja (con probabilidad de un 40%), enfrentándose en este último caso a una nueva decisión: estimular o no la demanda. Si no se hace nada (es decir, si no se estimula la demanda) la ganancia será de $40 y si se estimula (realizar publicidad) la respuesta puede ser moderada (con probabilidad de un 30%) y ganancia estimada de $20 o considerable (con probabilidad estimada de un 70%) y ganancia de $220.
Luego de hacer la representación en POM for Windows del problema seleccionamos Solve para encontrar la solución que representa la mayor ganancia esperada. El resultado que ofrece el software se muestra a continuación:
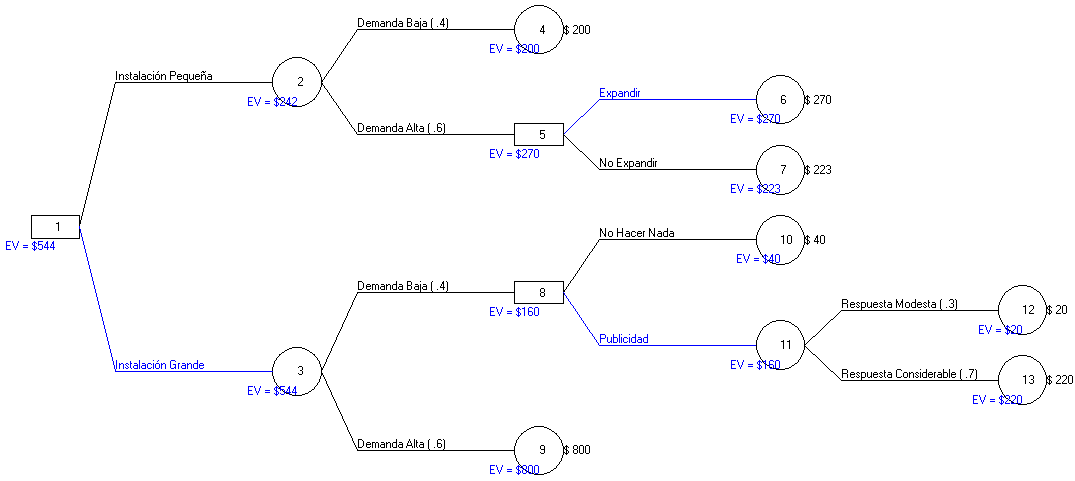
La gerencia por tanto debe construir la instalación grande con una ganancia esperada de $544 ($544=$160*0,4+$800*0,6 y además $160=$20*0,3+$220*0,7. La ganancia esperada asociada a la instalación pequeña es de $242). Notar que esta decisión (el tamaño de la instalación) es la única que se toma ahora. Las decisiones siguientes se toman después de ver si la demanda es baja o alta.
Para los usuarios que dispongan del software POM for Windows dejamos a continuación el archivo utilizado en este ejemplo para que pueda ser descargado. Alternativamente existen otros software que permiten la confección de árboles de decisión como PrecisionTree y TreePlan, ambos con opción de descarga gratuita durante un período de prueba.
[sociallocker]Ejemplo KPag 40[/sociallocker]