En el análisis del comportamiento de una línea de espera se suele considerar la premisa de que el tiempo entre llegada de los clientes se distribuye exponencial con parámetro lambda (λ). Si bien esta presunción es válida en muchas situaciones es conveniente realizar un diagnóstico de dicha situación a través de test estadísticos ad hoc. En este contexto el siguiente artículo aborda el problema de ajuste de una función de probabilidad teórica a una serie de datos empíricos que como se menciono anteriormente es un asunto de interés en el análisis de los sistemas de espera como así también en un sin número de aplicaciones estadísticas clásicas.
La data que utilizaremos en este tutorial fue obtenida del Libro Matching Supply with Demand: An Introduction to Operations Management![]() . Esta corresponde a las 686 llamadas que ha recibido un Call Center en un período de 4 horas según se muestra a continuación:
. Esta corresponde a las 686 llamadas que ha recibido un Call Center en un período de 4 horas según se muestra a continuación:
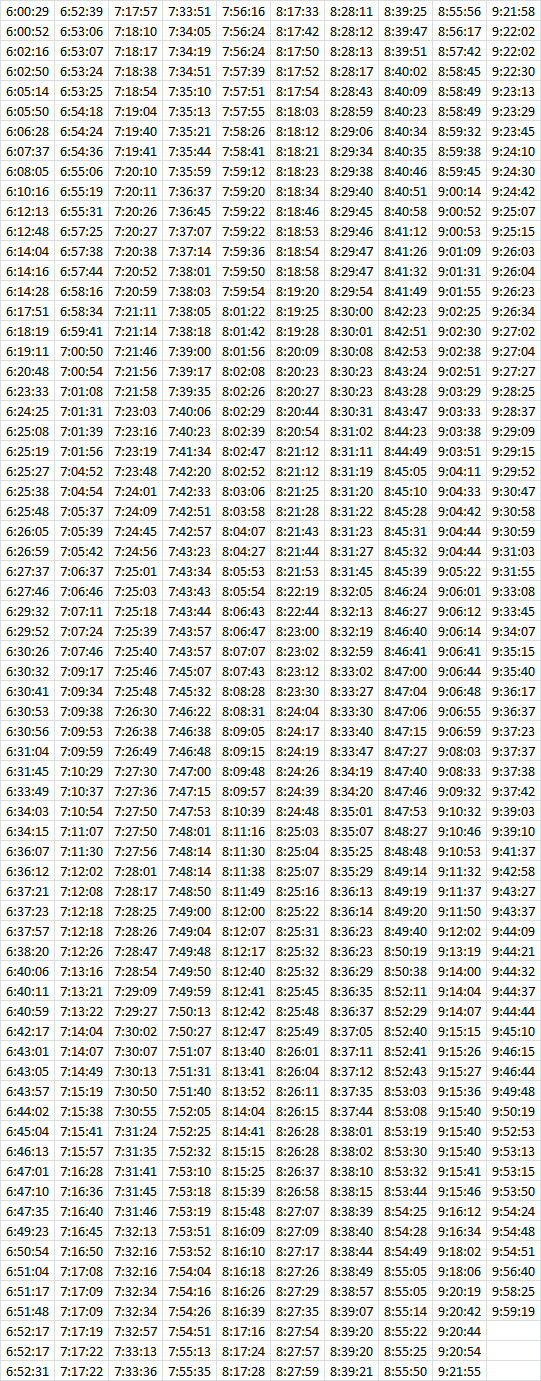
La pregunta que queremos responder es: ¿El tiempo entre llamada de los clientes se distribuye exponencial?. Análogamente ¿Qué función de probabilidad teórica ajusta de mejor forma los datos empíricos?. Para enfrentar dichas interrogantes utilizaremos el software Easyfit que hemos abordado en artículos anteriores para la confección de histogramas y análisis de estadísticas descriptivas.
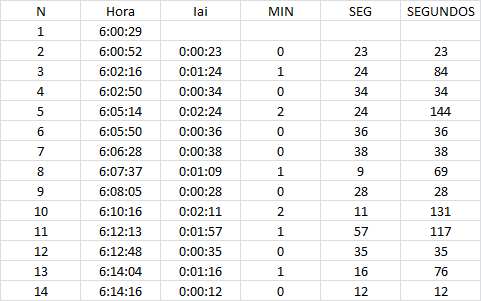
Preliminarmente ordenaremos los datos recolectados en una columna y procedemos a calcular el tiempo transcurrido entre cada llamada (Iai), por ejemplo, entre la primera y segunda llamada pasan 23 segundos, entre la segunda y tercera llamada pasan 1 minuto y 24 segundos (equivalente a 84 segundos) y así sucesivamente. A continuación se muestra un extracto de dicho procedimiento:
Con los tiempos entre llamadas en segundos (o su equivalencia en minutos si así se desea) se hace uso de Easyfit. Copiamos dichos tiempos en la columna A tal se muestra en la siguiente imagen y luego la opción «Ajustar distribuciones»:
Luego seleccionamos «OK»:
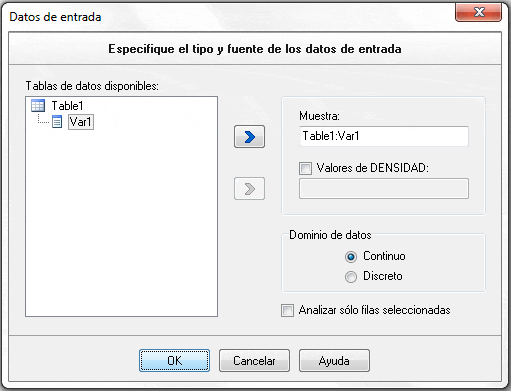
El programa se ejecuta y proporciona los resultados de los ajustes de los datos empíricos a un importante número de distribuciones teóricas, proporcionando una estimación de los parámetros respectivos.
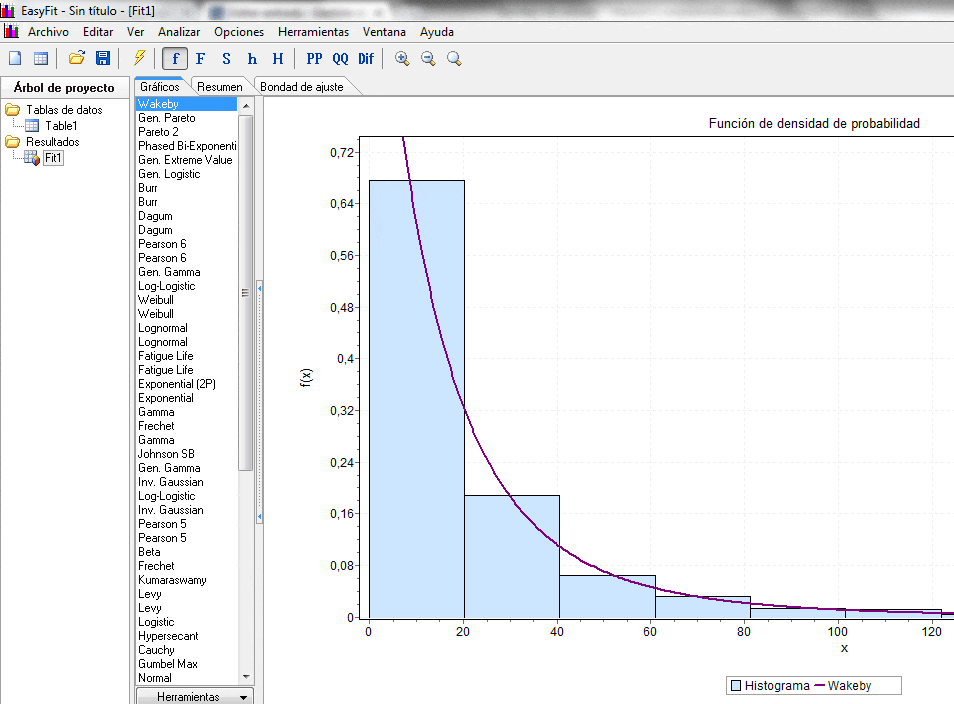
La distribución Wakeby es la que muestra el mejor ajuste, considerando los siguientes parámetros:
![]()
Adicionalmente podemos obtener los test de bondad de ajuste (en la pestaña «Bondad de ajuste»). Probablemente el más conocido de ellos es el test Chi-cuadrado (notar que las distribuciones han sido ordenadas en base a este criterio). También se puede obtener el detalle de las pruebas de hipótesis para distintos niveles de significancia estadística (valores de alfa).
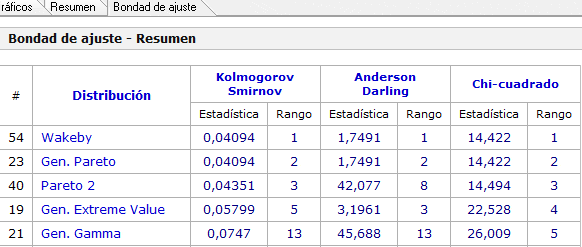
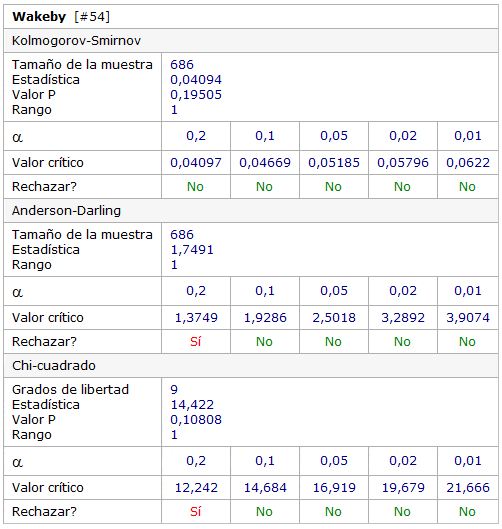
Una interpretación exhaustiva de los test de bondad de ajuste requiere de una discusión más detallada que escapa a los propósitos de este artículo. No obstante queda de manifiesto que existen herramientas computacionales que permite simplificar este tipo de análisis que es recurrente en el ámbito de la estadística y por cierto en el de la gestión de operaciones.