Los puntos atípicos (también denominados puntos aberrantes o outliers) siempre son un problema al momento de querer ajustar una serie de tiempo, o querer hacer predicciones para valores futuros. Recordamos al lector que una serie de tiempo se define como un conjunto de valores observados en un horizonte de tiempo y cumplen con ser equidistantes (por lo tanto, pueden ser observaciones tomadas por días, meses, trimestres, años, etc.).
Además, otra observación importante es que la decisión a tomar con respecto a qué se debe hacer con dichos valores es una elección que considera aspectos cuantitativos como cualitativos, ya que si bien se pueden utilizar test para decidir qué hacer con el punto, la decisión final siempre dependerá del modelador: pueden haber aspectos importantes en los datos que un test estadístico no es capaz de evaluar, y si el modelador cree que el punto debe estar por que representa un aspecto de la realidad, entonces se deberán asumir las consecuencias que implica dejar un punto que cuantitativamente puede ser considerado atípico.
En este artículo presentamos una forma de tratar puntos atípicos en una serie de tiempo. Los datos presentados se ordenan mensualmente en un horizonte de 8 años, y se utilizará R software (un programa freeware) para identificar y eliminar dichos puntos.
Siempre lo primero que debemos realizar al tener un conjunto de datos, es graficarlos para ver a priori su comportamiento. Este ejemplo utiliza una librería llamada “tseries”. Para descargarla, se debe seguir la siguiente instrucción: En el menú superior ir a la pestaña Paquetes:
Paquetes ==> Instalar Paquete(s)… ==> Seleccionar servidor ==> tseries
La siguiente porción de código permite cargar los datos, transformarlos en una serie y luego graficarlos.
#R Code
library(tseries) #Cargamos la librería
#Los datos están guardados en la variable data
data <- read.table("EjemploGEO.txt",header=T)
#La serie de tiempo está guardada en la varaible fit
fit <- ts(data,frequency=12,start=2000)
#Dividimos la pantalla de gráfico en dos
par(mfrow=c(1,2))
#Graficamos la serie de tiempo y una caja con bigotes
plot(fit)
boxplot(fit)
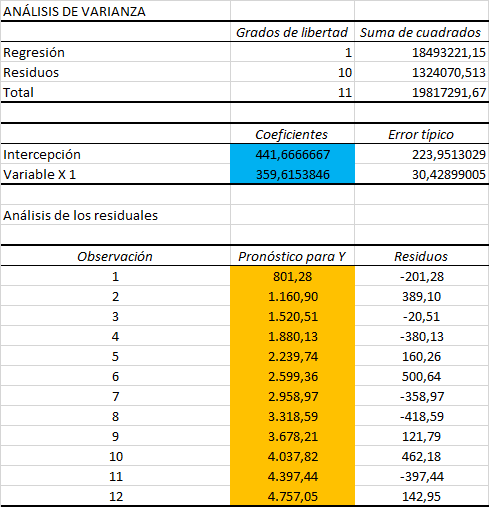
El resultado se puede apreciar en la siguiente imagen:
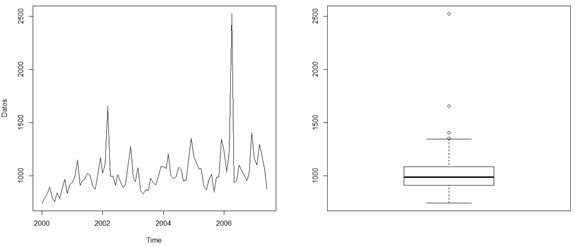
Como se puede ver, gráficamente podemos identificar dos puntos aberrantes, cerca del año 2002 y 2006. Además, un análisis mediante la caja con bigotes nos muestra cuatro puntos aberrantes. Este diagrama puede ser un poco más estricto, por lo tanto acá es importante destacar que es decisión del modelador sacar los cuatro, sólo dos (los de mayor impacto que se ven en el gráfico de la izquierda) o ninguno.
Para este ejemplo, consideraremos que vamos a sacar sólo los puntos que generan un mayor impacto en la serie, y son los que se pueden ver en el gráfico de la izquierda.
El análisis gráfico nos ayuda pero nunca es concluyente. Por lo anterior debemos utilizar siempre métodos cuantitativos para identificar los puntos (recordando nuevamente que la decisión sobre qué hacer con ellos depende tanto de factores cuantitativos como cualitativos).
Para poder identificar puntos outliers en la serie de tiempo, ocuparemos la librería “tsoutliers” la cual se puede descargar de la misma forma enseñada anteriormente.
#R Code library(tsoutliers) #Cargamos la librería #El comando tso identifica los puntos atípicos de la serie outliers <- tso(fit) #Graficamos la nueva serie plot(outliers)
El resultado se muestra a continuación:
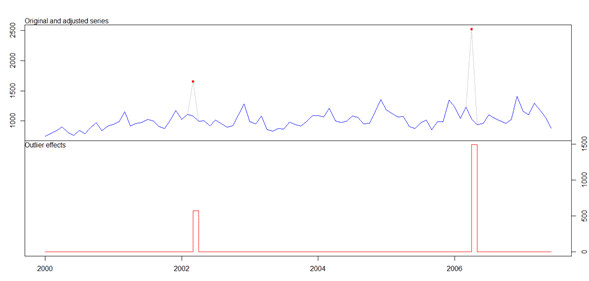
Podemos ver que esta función logra identificar (y pone en rojo) los puntos que considera aberrantes en la serie, y no sólo hace eso, sino que gráfica una serie “ajustada” (en azul), calculando un nuevo valor para dichos puntos en base a la información de los otros puntos pertenecientes a los datos.
¿Qué hacer con los puntos aberrantes?: Podemos sacarlos, modificarlos o dejarlos como están. Si los sacamos perdemos información; pero si los dejamos como están afectarán en la predicción de los valores futuros.
Una primera aproximación en estos casos siempre es calcular un promedio de los valores que están cerca del punto donde se produce el dato atípico, además, los estadísticos han desarrollado métodos más sofisticados para tratar con ellos, y dejamos este estudio al lector.
Como mencionamos anteriormente, esta función genera un valor que se ajusta de acuerdo al comportamiento de los datos (como se puede ver en el gráfico azul), por lo que utilizaremos dichos valores para ajustar una nueva serie, la cual tendrá los puntos aberrantes corregidos (dejamos también al estudio del lector la forma en que esta función modifica los datos, lo cual se puede encontrar en la documentación de la función disponible vía web).
#R Code #Obtenemos los valores modificados newserie <- outliers$yadj #Dividimos la pantalla de gráficos en 2 par(mfrow=c(1,2)) #Graficamos la serie antigua y la nueva plot(fit) plot(newserie)
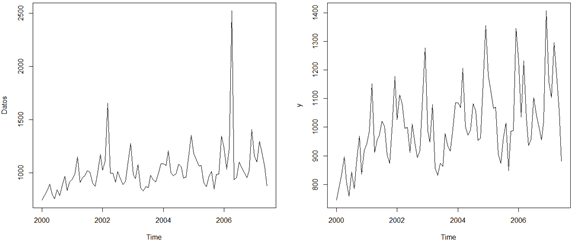
Podemos ver la nueva forma que tiene la serie, al tener valores modificados para los puntos atípicos (cuidado: la serie ha cambiado su forma drásticamente debido a los puntos aberrantes, pero el efecto se incrementa ya que ha cambiado la escala a la que se muestran ambos gráficos, notar que en el de la izquierda llega hasta 2.500 y ahora sólo hasta 1.400).
Como hemos podido ver, este simple método nos ha permitido hacer un tratamiento sobre los puntos atípicos identificados en la serie de datos. Como hemos mencionado reiteradamente, existen varios métodos para poder hacer esto, y la decisión final siempre tendrá una parte subjetiva que depende del modelador, ya que los criterios pueden variar, y puede ser que el origen de los datos justifique (y permita) la existencia de los puntos aberrantes. Para concluir, con la modificación realizada ahora si podemos pensar en predecir los valores futuros de la serie.


![\lambda =60/50=1,2[fallas/hora]](http://s0.wp.com/latex.php?latex=%5Clambda+%3D60%2F50%3D1%2C2%5Bfallas%2Fhora%5D&bg=ffffff&fg=000000&s=0 "\lambda =60/50=1,2[fallas/hora]") . Luego la distribución exponencial del tiempo entre fallas se representa por
. Luego la distribución exponencial del tiempo entre fallas se representa por =1,2e^{-1,2t}, t>0") .
.
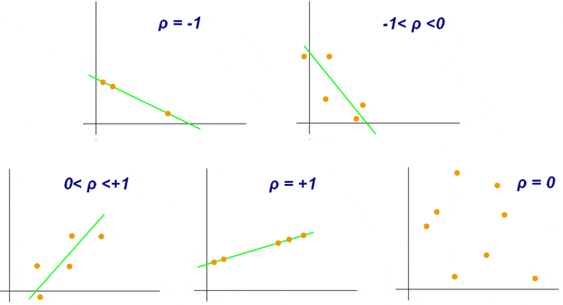
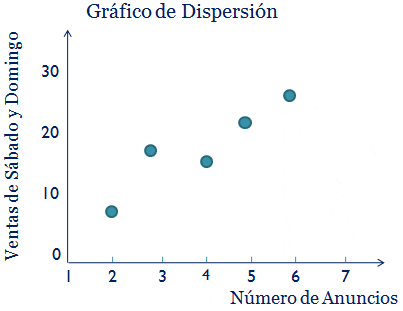
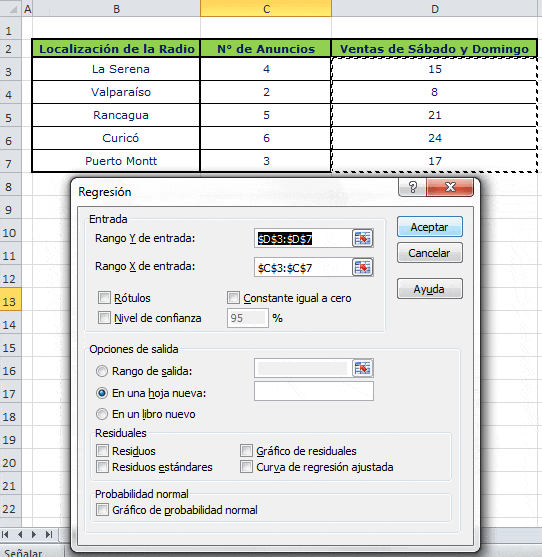
 y el Coeficiente de Determinación r Cuadrado (r²)")
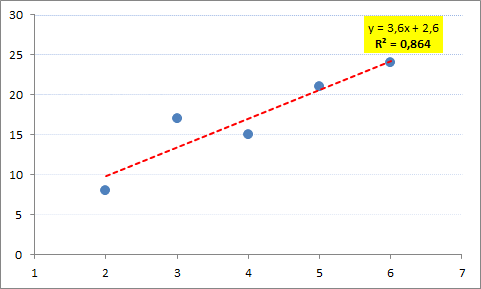



 .
.