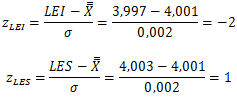
Cuando los clientes llegan a un servicio de forma totalmente aleatoria (es decir, no hay forma de pronosticar cuándo va a llegar alguien) la función de densidad de probabilidad para describir la cantidad de llegadas durante un tiempo determinado se representa por la Distribución de Poisson y automáticamente la distribución del tiempo entre llegadas sigue una Distribución Exponencial según lo expuesto en el artículo Propiedad de Falta de Memoria o Amnesia de la Distribución Exponencial.
En este contexto la fórmula que permite calcular la probabilidad exacta de  llegadas dentro de un período
llegadas dentro de un período  es la siguiente:
es la siguiente:
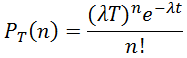
Consideremos por ejemplo un taller que se dedica a labores de reparación y que la llegada de éstos diariamente se comporta de forma aleatoria con una tasa de 10 trabajos diarios. ¿Cuál es la probabilidad de que no lleguen trabajos durante una hora cualquiera bajo el supuesto que el taller opera 8 horas al día?.
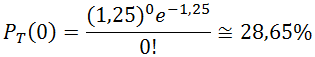
Notar que ![\lambda =\frac{10}{8}=1,25[\frac{trabajos}{hora}]](http://s0.wp.com/latex.php?latex=%5Clambda+%3D%5Cfrac%7B10%7D%7B8%7D%3D1%2C25%5B%5Cfrac%7Btrabajos%7D%7Bhora%7D%5D&bg=ffffff&fg=000000&s=0 "\lambda =\frac{10}{8}=1,25[\frac{trabajos}{hora}]") . Es decir, la probabilidad de no recibir trabajos durante una hora cualquiera es aproximadamente a un 28,65%.
. Es decir, la probabilidad de no recibir trabajos durante una hora cualquiera es aproximadamente a un 28,65%.
Asumamos ahora una nueva situación. Un proceso que tiene una tasa promedio de llegada de 6 clientes por hora (![\lambda =6[clientes/hora]](http://s0.wp.com/latex.php?latex=%5Clambda+%3D6%5Bclientes%2Fhora%5D&bg=ffffff&fg=000000&s=0 "\lambda =6[clientes/hora]") ) y se desea evaluar cuál es la probabilidad de que lleguen exactamente 0, 1, 2,…,n clientes en un intervalo de tiempo de 0,5 horas (30 minutos). El siguiente vídeo proporciona una simulación de dicho escenario:
) y se desea evaluar cuál es la probabilidad de que lleguen exactamente 0, 1, 2,…,n clientes en un intervalo de tiempo de 0,5 horas (30 minutos). El siguiente vídeo proporciona una simulación de dicho escenario:
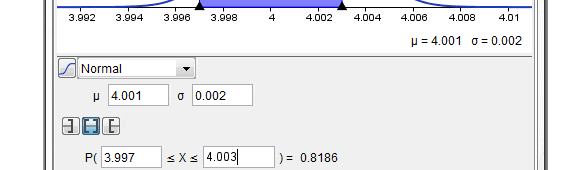
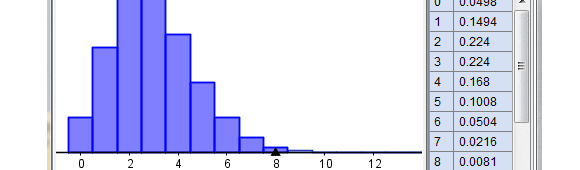
En el gráfico, el área amarilla, por ejemplo, significa exactamente la probabilidad que 3 personas lleguen en las 0,5 horas. El área amarilla más el área roja, por ejemplo, significa la probabilidad de que lleguen 2 o 3 personas en los 30 minutos.
Adicionalmente haciendo uso del software Geogebra y su herramienta cálculos de probabilidad, se puede representar la Distribución de Poisson para los parámetros descritos anteriormente de forma de obtener rápidamente los resultados para distintos números de llegadas (notar que la Distribución de Poisson es discreta).



![\lambda =60/50=1,2[fallas/hora]](http://s0.wp.com/latex.php?latex=%5Clambda+%3D60%2F50%3D1%2C2%5Bfallas%2Fhora%5D&bg=ffffff&fg=000000&s=0 "\lambda =60/50=1,2[fallas/hora]") . Luego la distribución exponencial del tiempo entre fallas se representa por
. Luego la distribución exponencial del tiempo entre fallas se representa por =1,2e^{-1,2t}, t>0") .
.
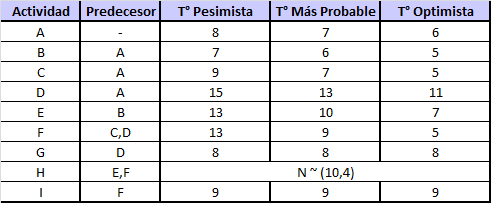
") y los tiempos están en días.
y los tiempos están en días.}{6}") , por ejemplo,
, por ejemplo, }{6}=7") . Adicionalmente la varianza se obtiene de
. Adicionalmente la varianza se obtiene de ^{2}}{36}") , por ejemplo,
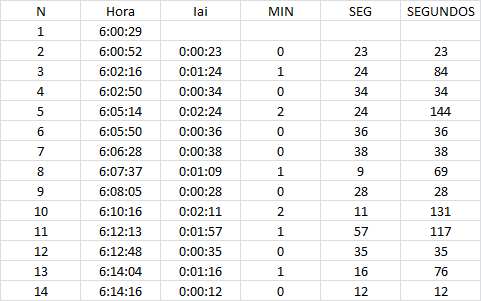
, por ejemplo, ^{2}}{36}=\frac{1}{9}\cong 0,111") . Con la ayuda de Excel resulta sencillo replicar el procedimiento para el resto de las actividades como se muestra a continuación:
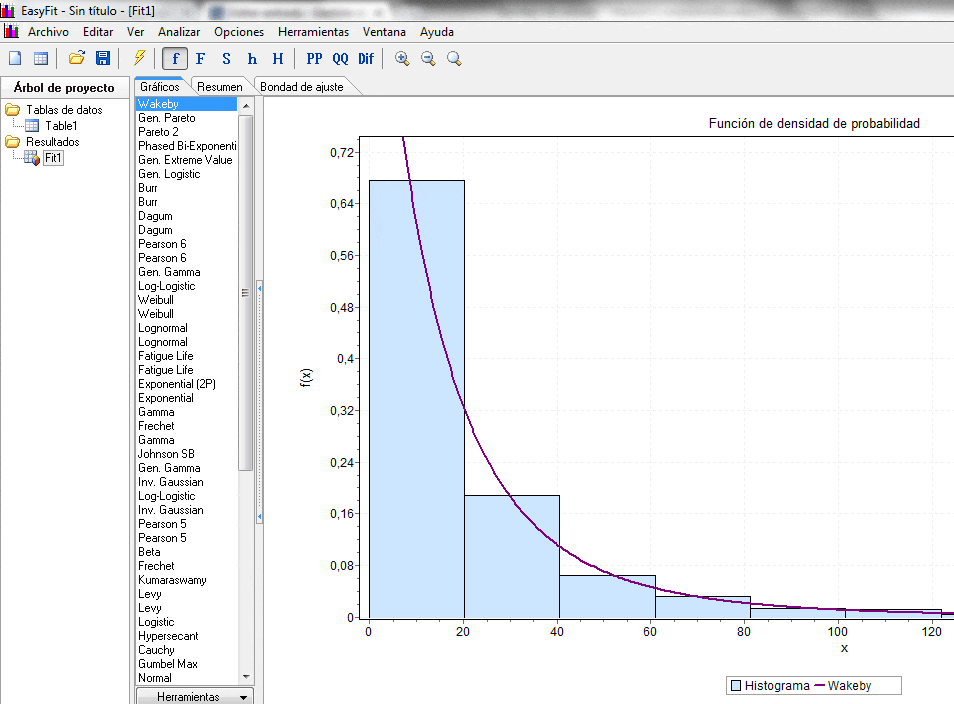
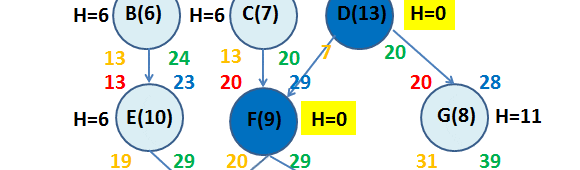
. Con la ayuda de Excel resulta sencillo replicar el procedimiento para el resto de las actividades como se muestra a continuación: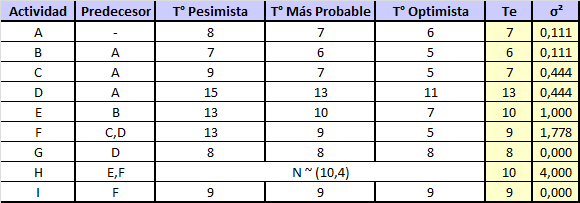

![\mathbb{P}[T<40]=\mathbb{P}[Z_{\alpha }<\frac{40-39}{\sum {\sigma _{RC}}^{2}}]=\frac{40-39}{\sqrt{(\frac{1}{9})+(\frac{4}{9})+(\frac{16}{9})+4}}\cong0,6544](http://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D%5BT%3C40%5D%3D%5Cmathbb%7BP%7D%5BZ_%7B%5Calpha+%7D%3C%5Cfrac%7B40-39%7D%7B%5Csum+%7B%5Csigma+_%7BRC%7D%7D%5E%7B2%7D%7D%5D%3D%5Cfrac%7B40-39%7D%7B%5Csqrt%7B%28%5Cfrac%7B1%7D%7B9%7D%29%2B%28%5Cfrac%7B4%7D%7B9%7D%29%2B%28%5Cfrac%7B16%7D%7B9%7D%29%2B4%7D%7D%5Ccong0%2C6544&bg=ffffff&fg=000000&s=0 "\mathbb{P}[T<40]=\mathbb{P}[Z_{\alpha }<\frac{40-39}{\sum {\sigma _{RC}}^{2}}]=\frac{40-39}{\sqrt{(\frac{1}{9})+(\frac{4}{9})+(\frac{16}{9})+4}}\cong0,6544")
![\mathbb{P}[T>41]=\mathbb{P}[1-Z_{\alpha }<\frac{41-39}{\sum {\sigma _{RC}}^{2}}]=\frac{41-39}{\sqrt{(\frac{1}{9})+(\frac{4}{9})+(\frac{16}{9})+4}}\cong0,2134](http://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D%5BT%3E41%5D%3D%5Cmathbb%7BP%7D%5B1-Z_%7B%5Calpha+%7D%3C%5Cfrac%7B41-39%7D%7B%5Csum+%7B%5Csigma+_%7BRC%7D%7D%5E%7B2%7D%7D%5D%3D%5Cfrac%7B41-39%7D%7B%5Csqrt%7B%28%5Cfrac%7B1%7D%7B9%7D%29%2B%28%5Cfrac%7B4%7D%7B9%7D%29%2B%28%5Cfrac%7B16%7D%7B9%7D%29%2B4%7D%7D%5Ccong0%2C2134&bg=ffffff&fg=000000&s=0 "\mathbb{P}[T>41]=\mathbb{P}[1-Z_{\alpha }<\frac{41-39}{\sum {\sigma _{RC}}^{2}}]=\frac{41-39}{\sqrt{(\frac{1}{9})+(\frac{4}{9})+(\frac{16}{9})+4}}\cong0,2134")
![\mathbb{P}[T\geq40]+\mathbb{P}[T\leq 41]=0,1322](http://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D%5BT%5Cgeq40%5D%2B%5Cmathbb%7BP%7D%5BT%5Cleq+41%5D%3D0%2C1322&bg=ffffff&fg=000000&s=0 "\mathbb{P}[T\geq40]+\mathbb{P}[T\leq 41]=0,1322")